Asynchronous programming with Go!
Gaurav Singha Roy
7 Jun 2018
•
6 min read

When I started learning Go, a couple of its features had really drawn me towards it. The first was the ease in which pointers could be used. The second was the ease with which its asychronous capabilities could be used. In this blog, I would try to use the different ways you can solve a very simple problem.
Let us take a very common example where we would simply try to build a program which would check if a set of websites/urls are up and running or not. For this example, I have picked 5 airline websites.
1. The Synchronous way
The most easiest way to handle this would be to simple iterate over your slice of urls and try to make an HTTP GET request to the url. Check out the following code snippet.
package main
import (
"fmt"
"net/http"
)
func main() {
// A slice of sample websites
urls := []string{
"https://www.easyjet.com/",
"https://www.skyscanner.de/",
"https://www.ryanair.com",
"https://wizzair.com/",
"https://www.swiss.com/",
}
for _, url := range urls {
checkUrl(url)
}
}
//checks and prints a message if a website is up or down
func checkUrl(url string) {
_, err := http.Get(url)
if err != nil {
fmt.Println(url, "is down !!!")
return
}
fmt.Println(url, "is up and running.")
}
The code snippet is fairly basic and when I run it, I get the following output.
[https://www.easyjet.com/](https://www.easyjet.com/) is up and running.
[https://www.skyscanner.de/](https://www.skyscanner.de/) is up and running.
[https://www.ryanair.com](https://www.ryanair.com) is up and running.
[https://wizzair.com/](https://wizzair.com/) is up and running.
[https://www.swiss.com/](https://www.swiss.com/) is up and running.
This is good, but in this case we check if each website is up one by one. An ideal solution would be to handle this non-linearly and check if they are up concurrently.
2. Go routines
Go ships with it go routines, which executes a function asynchronously. It is a lightweight thread of execution.The keyword for it is go . Lets say, you have a function f() and you would like to execute that in a go routine, then simply use, go f(). So in the above example, all we need to do is simply add the keyword go before the function call for checkUrl, and the function would be executed asynchronously in a go routine.
package main
import (
"fmt"
"net/http"
)
func main() {
// A slice of sample websites
urls := []string{
"https://www.easyjet.com/",
"https://www.skyscanner.de/",
"https://www.ryanair.com",
"https://wizzair.com/",
"https://www.swiss.com/",
}
for _, url := range urls {
go checkUrl(url)
}
}
//checks and prints a message if a website is up or down
func checkUrl(url string) {
_, err := http.Get(url)
if err != nil {
fmt.Println(url, "is down !!!")
return
}
fmt.Println(url, "is up and running.")
}
Just the line# 18 is different where we have added the go keyword. Now, if we execute this code snippet, we will notice that it ends immediately and does not print anything. Let me explain why that happened.
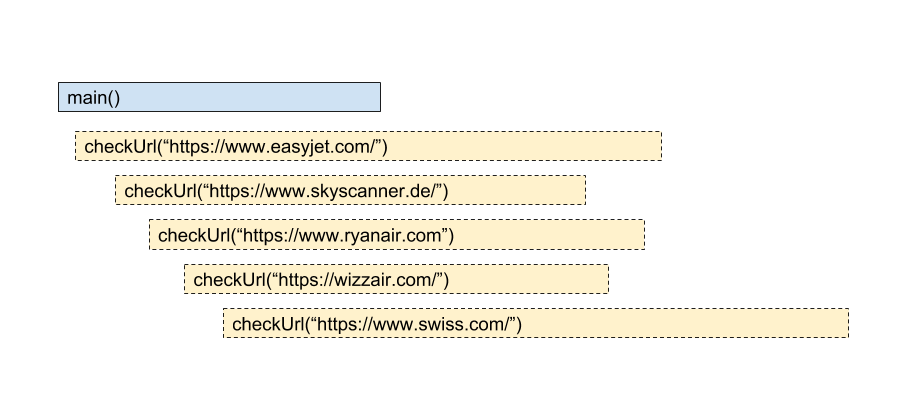
The above diagram represents a rough timeline of the execution of all the routines. The go routines are executed within the main() routine. What we can see is the execution of each of the go routines takes longer than the execution of the main() routine, i.e., the main routine exits before all the go routines have finished execution.
Now how can we not allow the main routine to not exit so soon. One simple solution would be to add a sleep function in the end of course :)
package main
import (
"fmt"
"net/http"
"time"
)
func main() {
// A slice of sample websites
urls := []string{
"https://www.easyjet.com/",
"https://www.skyscanner.de/",
"https://www.ryanair.com",
"https://wizzair.com/",
"https://www.swiss.com/",
}
for _, url := range urls {
// Call the function check
go checkUrl(url)
}
time.Sleep(5 * time.Second)
}
//checks and prints a message if a website is up or down
func checkUrl(url string) {
_, err := http.Get(url)
if err != nil {
fmt.Println(url, "is down !!!")
return
}
fmt.Println(url, "is up and running.")
}
Now if we execute the code, we get the following output.
[https://www.ryanair.com](https://www.ryanair.com) is up and running.
[https://www.swiss.com/](https://www.swiss.com/) is up and running.
[https://www.skyscanner.de/](https://www.skyscanner.de/) is up and running.
[https://wizzair.com/](https://wizzair.com/) is up and running.
[https://www.easyjet.com/](https://www.easyjet.com/) is up and running.
Notice, that the order of the output is different than that of our urls slice. This is because they have been executed asynchronously. Now, having a sleep function is not a good solution. Please note that when you execute this, you might have a different order in your output.
In the next section, we will talk about a primitive way to handle this with Wait Groups.
3. Wait Groups
The sync package of Go provides some basic synchronization primitives such as mutexes, WaitGroups, etc. In this example, we would be using the WaitGroup.
A WaitGroup waits for a collection of go routines to finish. Just simply add the number of go routines to wait for in the main routine. Let us use it in our example
package main
import (
"fmt"
"net/http"
"sync"
)
func main() {
// A slice of sample websites
urls := []string{
"https://www.easyjet.com/",
"https://www.skyscanner.de/",
"https://www.ryanair.com",
"https://wizzair.com/",
"https://www.swiss.com/",
}
var wg sync.WaitGroup
for _, u := range urls {
// Increment the wait group counter
wg.Add(1)
go func(url string) {
// Decrement the counter when the go routine completes
defer wg.Done()
// Call the function check
checkUrl(url)
}(u)
}
// Wait for all the checkWebsite calls to finish
wg.Wait()
}
//checks and prints a message if a website is up or down
func checkUrl(url string) {
_, err := http.Get(url)
if err != nil {
fmt.Println(url, "is down !!!")
return
}
fmt.Println(url, "is up and running.")
}
In line#18, we have defined a WaitGroup instance. Now check line#22, where we increment with 1 just before we execute the go routine. In line#25, we have a deferred call to the Done()method of WaitGroup. This will be a signal to the WaitGroup to let it know that the execution of the go routine is complete. Finally in line#31, we added the Wait() method call. This will let the main routine to simply wait till all the Done() calls of the WaitGroup have been executed. If we now execute this code snippet, we will see that we get an asynchronous output similar to the previous section.
WaitGroup generally should be used for much low level designs. For a better communication, we should use channels. Let us jump into that in the next section
4. Channels
One issue with the solution above was that, there was no communication between the function checkUrl back to the go routine. This is essential for a better communication. In comes go channels. Channels provide a convenient, typed way to send and receive messages with the operator <-. Its usage is
ch <- v // Send v to channel ch.
v := <-ch // Receive from ch, and
// assign value to v.
Before we use this for our example, let us try to use it for a much simpler use case.
package main
import "fmt"
func sum(a int, b int, c chan int) {
c <- a + b // send sum to c
}
func main() {
c := make(chan int)
go sum(20, 22, c)
x := <-c // receive from c
fmt.Println(x)
}
Here we have a simple sum function which expects a channel as an input parameter as well. In line#6 we simply add the result to the channel. The channel is first instantiated in the main routine with the type int. And in line#12, we simply receive the result for the channel. So sending from line#6 and receiving from line#12.
Now, let us use this for our example.
package main
import (
"fmt"
"net/http"
)
func main() {
// A slice of sample websites
urls := []string{
"https://www.easyjet.com/",
"https://www.skyscanner.de/",
"https://www.ryanair.com",
"https://wizzair.com/",
"https://www.swiss.com/",
}
c := make(chan urlStatus)
for _, url := range urls {
go checkUrl(url, c)
}
result := make([]urlStatus, len(urls))
for i, _ := range result {
result[i] = <-c
if result[i].status {
fmt.Println(result[i].url, "is up.")
} else {
fmt.Println(result[i].url, "is down !!")
}
}
}
//checks and prints a message if a website is up or down
func checkUrl(url string, c chan urlStatus) {
_, err := http.Get(url)
if err != nil {
// The website is down
c <- urlStatus{url, false}
} else {
// The website is up
c <- urlStatus{url, true}
}
}
type urlStatus struct {
url string
status bool
}
In line#45, we have declared a struct called urlStatus. This simply contains two fields, the url and the status if it is up or not. We will use this as the type for the communication in the channel. Line#36, the checkUrl function has been modified to also accept a channel as an input. Instead of returning a result, we will send the result as an instance of urlStatus to the channel. Lets jump to the main routine now. We instantiate this channel with type urlStatus in line#18. We will pass this channel as an input parameter in the function calls for checkUrl. We will now instantiate a slice result which simply will collect all the results which we will receive from the channel (Line#23). In each element of the result slice, we simply add the channel response (Line#25). All we have to do now is to check these values and print out the appropriate message.
There would have been of course other ways to solve the same example, but here we opted for using our own type to show the typed features of the channels and how it can be used to build some primitive Actor-Model like applications.
I hope this tutorial was helpful, and happy “Gophing” !
Gaurav Singha Roy
I am an experienced software developer and an open source enthusiast with 8 years of experience in software development. I have worked on various different environments with experience in building robust applications in Scala, Go and Ruby. I am passionate about programming and share strong interests for Open source, Functional programming, Web semantics, Graph databases and Big data. I am also a strong believer of Agile and enjoy taking ownership of processes, be it Kanban or Scrum. In my spare time, I read, write, and cook five nights a week. Currently, I am working as a senior developer in Berlin.
See other articles by Gaurav

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!